| ИВМ СО РАН | Поиск |
| Отчеты ИВМ СО РАН |
Отчет ИВМ СО РАН за 2013 год
Проекты СО РАН
- Программа сибирского отделения РАН «Телекоммуникационные и мультимедийные ресурсы СО РАН»
- Программа сибирского отделения РАН «Высокопроизводительные вычисления СО РАН»
- Междисциплинарные интеграционные проекты
- Проекты СО РАН, выполняемые совместно со сторонними научными организациями
- Экспедиционные проекты СО РАН
Программа сибирского отделения РАН «Высокопроизводительные вычисления СО РАН»
Программа сибирского отделения РАН «Высокопроизводительные вычисления СО РАН»
Координатор программы: академик РАН Б. Г. Михайленко
Руководитель от КНЦ СО РАН: член-корреспондент РАН В. В. Шайдуров
Ответственный исполнитель от ИВМ СО РАН: к.т.н. С. В. Исаев
Исполнители: Д. Д. Кононов, А. В. Малышев
1. Оптимизировано и модернизировано системное программное обеспечение вычислительного кластера МВС-1000 классической архитектуры и рабочей станции Flagman RX240T8.2 на основе графических вычислителей. Проводились работы по технической поддержке и обеспечению доступа пользователей к вычислительным ресурсам. Произведено обновление системного программного обеспечения гибридной вычислительной системы на основе GPU Flagman RX240T8.2. Установлены последние обновления прикладного программного обеспечения для математических расчетов: MATLAB, Simulink и Parallel Computing Toolbox, а также дополнительные лицензии для многопользовательского доступа.
Поддерживалось функционирование находящегося в совместном использовании кластера СФУ IBM System x3755. Помимо научных расчетов этот кластер обслуживает практические занятия Института математики и фундаментальной информатики СФУ по курсам «Параллельные вычисления» и «Высокопроизводительные вычисления».
2. Произведен анализ статистики использования централизованных вычислительных ресурсов. Средняя загрузка кластеров по данным ведущейся статистики составляет около 68% (от 16% до 100% в разные периоды). Из общего объема около 60% загрузки дают задачи пользователей Института физики СО РАН, 35% — Институт химии и химической технологии СО РАН, 5% — Институт вычислительного моделирования СО РАН.
Загрузка кластера в отдельные месяцы достигает 100% (Рис. V.2) и по сравнению с 2012 годом возросла в среднем на 10%. Часть пользователей, по-прежнему, запускает отлаженные задачи на более мощных вычислительных системах в других научных центрах Новосибирска, Томска и Москвы, а также кластере Сибирского федерального университета.
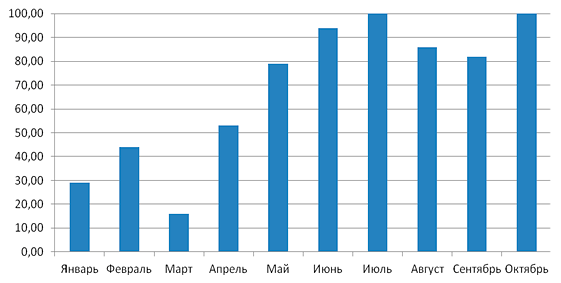
Рис. V.2. Загрузка кластера МВС1000/ИВМ
Все многоядерные модули для рационального использования их ресурсов добавлены в специальную пользовательскую очередь задач, требующих более 48 вычислительных ядер. На всех вычислительных кластерах с телекоммуникационным доступом ведется статистика использования ресурсов и поддерживается телекоммуникационный доступ из научно-образовательной сети на скорости до 1 Гбит/с, а из сетей общего пользования до 60 Мбит/с.
Выполнялись работы по установке и обновлению программного обеспечения, по техническому обслуживанию и администрированию используемых в Институте вычислительных кластеров с телекоммуникационным доступом. На всех ключевых узлах вычислительной сети установлена распределенная система мониторинга ресурсов и отслеживания статусов запущенных сервисов ZABBIX. Система помогает анализировать функционирование узлов и оперативно оповещает администраторов о возникающих проблемах.
Введены в эксплуатацию два 64-ядерных вычислительных модуля в составе кластера МВС-1000, что позволило увеличить его пиковую производительность в 2.3 раза до 2.04 Тфлопс, а производительность по Linpack до 1.51 Тфлопс.
| Направление исследований | Запусков задач | Организация | Вклад в загрузку (%) |
|---|---|---|---|
| Молекулярная динамика | 4329 | ИФ СО РАН | 60 |
| Молекулярная динамика | 715 | ИХХТ СО РАН | 35 |
| Вычислительная механика | 284 | ИВМ СО РАН | 1 |
| Прочее | 1133 | ИВМ, СибГТУ и др. | 4 |
| ВСЕГО | 6461 | 100 |
Таблица V.1 Статистика использования МВС-1000/146 для расчетов (топ-лист)
Исходя из статистики видно, что в 2013 году количество запусков кратковременных задач уменьшилось более чем в 4 раза по сравнению с 2012 годом, что свидетельствует об уменьшении количества отладочных задач и переходу к длительным расчетам.
За счет средств программы в 2013 приобретен и установлен на вторую серверную площадку источник бесперебойного питания на 8 КВт, что позволило установить и ввести в эксплуатацию приобретенные в 2012 два 64-ядерных вычислительных модуля в составе кластера МВС-1000.
Организовано резервное копирование данных вычислительного кластера на сетевое хранилище Synology RackStation RS3412RPxs объемом 30 ТВ. К хранилищу обеспечен доступ вычислительных серверов с общей пропускной способностью интерфейсов 4 Гб/с.
3. Произведен анализ тенденций развития высокопроизводительных вычислений на основе которого составлена спецификация и произведена закупка высокопроизводительного вычислительного сервера ASUS ESC4000 G2 (2 Intel Xeon Phi 5110P, 2x1620W PSU). Сервер имеет следующие характеристики: 2 процессора Intel Xeon E5-2660 Sandy Bridge-EP (2200 MHz, LGA2011, L3 20480 Kb, 8 core), 2 сопроцессора Intel Xeon Phi 5110P (8 GB, 1.053 GHz, 60 core), оперативная память — 128 ГБ, HDD: 2000 TB.

Рис. V.3. Двухпроцессорный сервер с возможностью установки до 4-х сопроцессоров Intel Xeon Phi
Каждый из установленных сопроцессоров Xeon Phi 5110P имеет пиковую производительность до 1.01 терафлопс (двойной точности) и работает с памятью со скоростью в 320 ГБ/с. Таким образом, пиковая производительность нового сервера, учитывая производительность процессора Intel Xeon E5-2660 на уровне 0.14 терафлопс, составляет около 2.3 терафлопс. В отличие от специализированных программ для GPU, процессор XeonPhi выполняет х86 совместимые программы.
В качестве основного прикладного программного обеспечения для этого сервера приобретен специализированный набор Intel Cluster Studio XE for Linux OS, включающего в себя следующие компоненты:
- интегрированный набор инструментов для разработки кластерных приложений;
- высокопроизводительная библиотека MPI;
- высокопроизводительные компиляторы C++ и Fortran и мощные модели параллельности для многоядерных процессоров;
- инструменты анализа корректности и инструменты профилирования для приложений общего доступа и для распределенных и гибридных приложений.
Среда разработки содержит мощный механизм поиска и устранения ошибок на этапе написания кода, что позволяет создавать более быстродействующие, масштабируемые и надежные приложения. Она рассчитана на оптимизацию приложений под уже выпускаемые и только планируемые к выпуску процессоры Intel, включая мощную серверную платформу с сопроцессорами Intel Xeon Phi. Пакет Intel Cluster Studio предлагает разработчикам множество новых функций и возможностей, включая улучшенный компилятор и системные библиотеки с повышенной производительностью. В состав включена обновленная библиотека MPI с повышенной отказоустойчивостью и расширенной поддержкой параллельной обработки. В частности, параллельная обработка на процессорах Intel теперь поддерживается в средах Linux, на языках программирования Fortan и C#.
Среда Intel Cluster Studio XE содержит все необходимые инструменты для создания качественных приложений с разделяемой памятью; кроме того, в нее добавлена поддержка распределенных и гибридных программ. Приложения, написанные или оптимизированные с использованием среды разработки, практически во всех случаях работают быстрее на отдельных компьютерах, серверах и кластерах.
(Отделы Информационно-телекоммуникационных технологий, Вычислительной математики, Вычислительной механики деформируемых сред)
| К началу | |